
Target Component Analysis
Sample profiling using target component analysis is a useful tool for determining the relative amount of a target substance present in a complex mixture or to search for characteristic components of your samples. It is widely used in application areas such as environmental screening or in the forensic determination of drugs of abuse. It is also important to be able to determine non-target components in areas of product adulteration and AnalyzerPro is able to cover these workflows with ease.
AnalyzerPro provides a simple and accurate way to create your target component libraries from the components found in a sample. Retention time or retention index (RI) information as well as spectral, all NIST format library match information and meta data can all be captured for each component. Additional confirmation criteria using specified ion ratios for components can also be set. Target component analysis also captures reliable component abundance information (height and area) for each sample that is processed.
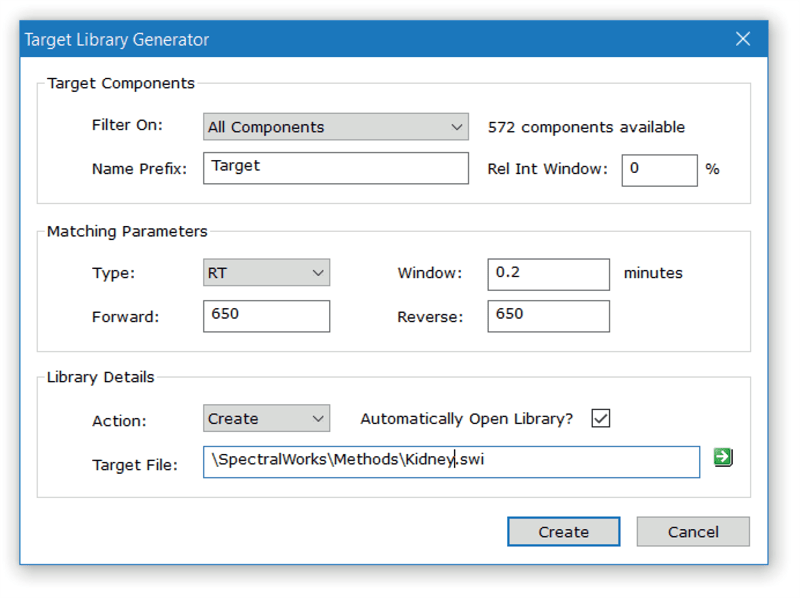
Figure 1. Create a target component library
Curation of target component libraries allows additional components to be added (appended) to the library, edited or deleted as required.
In the figure below, found components are shown in green and new non target components in blue. Target components that are not found are indicated by a red marker on the baseline.
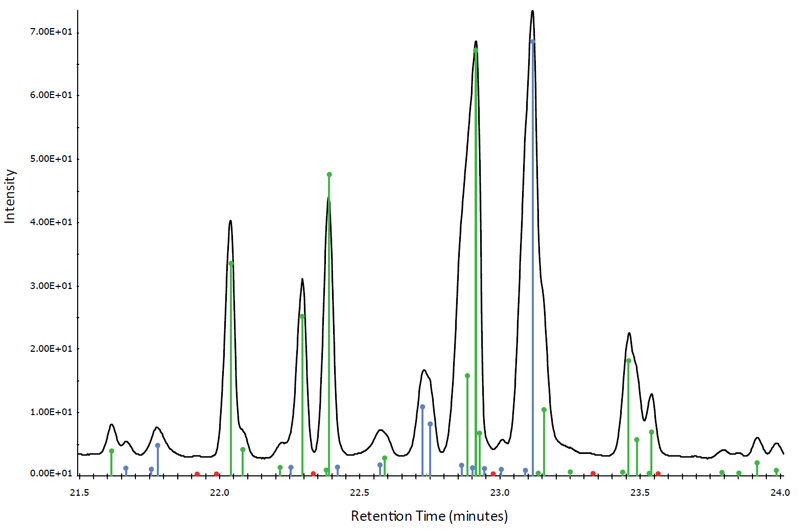
Figure 2. Found targets, not found targets and unknown targets
Components can be visualized using the component ions, the base peak, selected ions or the sum of the component ions for visual confirmation of the peak deconvolution. This allows you to clearly see the deconvoluted chromatographic components that may be hidden in your data. In the example below, there are six components found over the retention time window. The component chromatograms for each of those components as well as the TIC are shown.
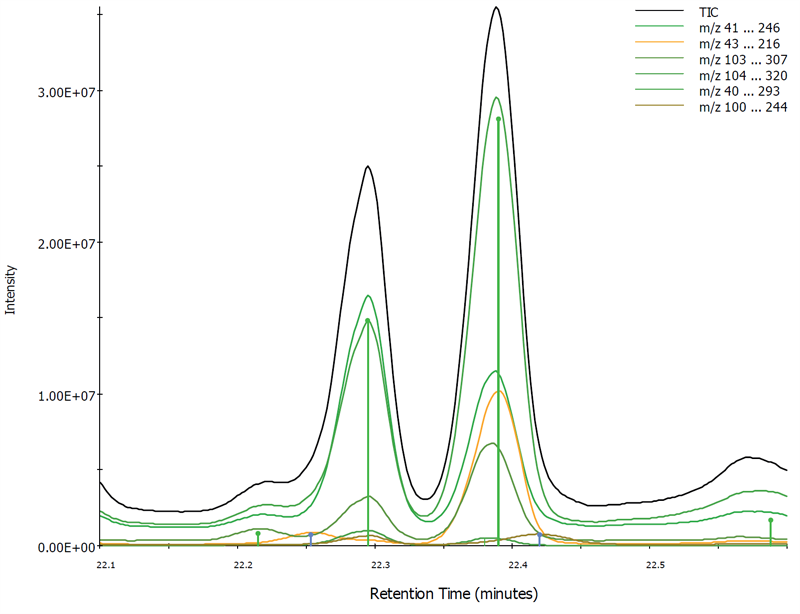
Figure 3. Chromatograms for the 6 found components and TIC
When processing samples, components can be quickly identified and reported as being found, not found or unknown. The unknown components are components that have been found in a sample which were not in the target component library. These components can subsequently be added to your library. When processing a sequence of samples, it is possible to automate this step such that when each new unknown component is detected it is added to the target library. In this way you can build up a comprehensive target library from all of your data files. This ‘super’ library can then be used for profiling multiple samples using MatrixAnalyzer and its PCA visualization tool.